Memory Layout of C Programs
A typical memory representation of C program consists of following
sections.
1. Text segment
2. Initialized data segment
3. Uninitialized data segment
4. Stack
5. Heap
2. Initialized data segment
3. Uninitialized data segment
4. Stack
5. Heap
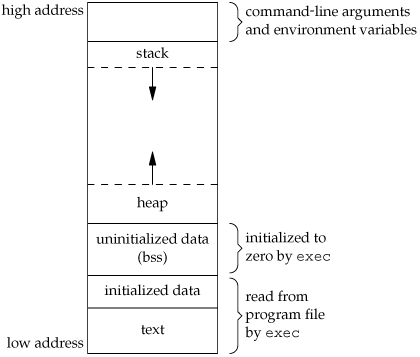
A typical memory layout of a running process
1. Text Segment:
A text segment , also known as a code segment or simply as text, is one of the sections of a program in an object file or in memory, which contains executable instructions.
A text segment , also known as a code segment or simply as text, is one of the sections of a program in an object file or in memory, which contains executable instructions.
As a memory region, a text segment may be placed below the heap or
stack in order to prevent heaps and stack overflows from overwriting it.
Usually, the text segment is sharable so that only a single copy
needs to be in memory for frequently executed programs, such as text editors,
the C compiler, the shells, and so on. Also, the text segment is often
read-only, to prevent a program from accidentally modifying its instructions.
2. Initialized Data Segment:
Initialized data segment, usually called simply the Data Segment. A data segment is a portion of virtual address space of a program, which contains the global variables and static variables that are initialized by the programmer.
Initialized data segment, usually called simply the Data Segment. A data segment is a portion of virtual address space of a program, which contains the global variables and static variables that are initialized by the programmer.
Note that, data segment is not read-only, since the values of the
variables can be altered at run time.
This segment can be further classified into initialized read-only
area and initialized read-write area.
For instance the global string defined by char s[ ] = “hello
world” in C and a C statement like int debug=1 outside the main (i.e. global)
would be stored in initialized read-write area. And a global C statement like
const char* string = “hello world” makes the string literal “hello world” to be
stored in initialized read-only area and the character pointer variable string
in initialized read-write area.
Ex: static int i = 10 will be stored in data segment and global
int i = 10 will also be stored in data segment
3. Uninitialized Data Segment:
Uninitialized data segment, often called the “bss” segment, named after an ancient assembler operator that stood for “block started by symbol.” Data in this segment is initialized by the kernel to arithmetic 0 before the program starts executing
Uninitialized data segment, often called the “bss” segment, named after an ancient assembler operator that stood for “block started by symbol.” Data in this segment is initialized by the kernel to arithmetic 0 before the program starts executing
uninitialized data starts at the end of the data segment and
contains all global variables and static variables that are initialized to zero
or do not have explicit initialization in source code.
For instance a variable declared static int i; would be contained
in the BSS segment.
For instance a global variable declared int j; would be contained in the BSS segment.
For instance a global variable declared int j; would be contained in the BSS segment.
4. Stack:
The stack area traditionally adjoined the heap area and grew the opposite direction; when the stack pointer met the heap pointer, free memory was exhausted. (With modern large address spaces and virtual memory techniques they may be placed almost anywhere, but they still typically grow opposite directions.)
The stack area traditionally adjoined the heap area and grew the opposite direction; when the stack pointer met the heap pointer, free memory was exhausted. (With modern large address spaces and virtual memory techniques they may be placed almost anywhere, but they still typically grow opposite directions.)
The stack area contains the program stack, a LIFO structure,
typically located in the higher parts of memory. On the standard PC x86
computer architecture it grows toward address zero; on some other architectures
it grows the opposite direction. A “stack pointer” register tracks the top of
the stack; it is adjusted each time a value is “pushed” onto the stack. The set
of values pushed for one function call is termed a “stack frame”; A stack frame
consists at minimum of a return address.
Stack, where automatic variables are stored, along with
information that is saved each time a function is called. Each time a function
is called, the address of where to return to and certain information about the
caller’s environment, such as some of the machine registers, are saved on the
stack. The newly called function then allocates room on the stack for its
automatic and temporary variables. This is how recursive functions in C can
work. Each time a recursive function calls itself, a new stack frame is used,
so one set of variables doesn’t interfere with the variables from another
instance of the function.
5. Heap:
Heap is the segment where dynamic memory allocation usually takes place.
Heap is the segment where dynamic memory allocation usually takes place.
The heap area begins at the end of the BSS segment and grows to
larger addresses from there.The Heap area is managed by malloc, realloc, and
free, which may use the brk and sbrk system calls to adjust its size (note that
the use of brk/sbrk and a single “heap area” is not required to fulfill the
contract of malloc/realloc/free; they may also be implemented using mmap to
reserve potentially non-contiguous regions of virtual memory into the process’
virtual address space). The Heap area is shared by all shared libraries and
dynamically loaded modules in a process.
Examples.
The size(1) command reports the sizes (in bytes) of the text,
data, and bss segments. ( for more details please refer man page of size(1) )
1. Check the following simple C program
#include <stdio.h>
int main(void)
{
return 0;
}
|
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
text data bss dec hex
filename
960 248 8 1216 4c0
memory-layout
2. Let us add one global variable in program, now check the size
of bss (highlighted in red color).
#include <stdio.h>
int global; /*
Uninitialized variable stored in bss*/
int main(void)
{
return 0;
}
|
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
text data bss dec hex
filename
960 248 12 1220 4c4
memory-layout
3. Let us add one static variable which is also stored in bss.
#include <stdio.h>
int global; /*
Uninitialized variable stored in bss*/
int main(void)
{
static int i; /* Uninitialized static variable stored in
bss */
return 0;
}
|
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
text data bss dec hex
filename
960 248 16 1224 4c8
memory-layout
4. Let us initialize the static variable which will then be stored
in Data Segment (DS)
#include <stdio.h>
int global; /*
Uninitialized variable stored in bss*/
int main(void)
{
static int i = 100; /* Initialized static variable stored
in DS*/
return 0;
}
|
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
text data bss dec hex
filename
960 252 12 1224 4c8
memory-layout
5. Let us initialize the global variable which will then be stored
in Data Segment (DS)
#include <stdio.h>
int global = 10; /*
initialized global variable stored in DS*/
int main(void)
{
static int i = 100; /* Initialized static variable stored
in DS*/
return 0;
}
|
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
text data bss dec hex
filename
960 256 8 1224 4c8
memory-layout
Structures Vs Unions
With a union, you're only supposed to use one of
the elements, because they're all stored at the same spot. This makes it useful
when you want to store something that could be one of several types. A struct,
on the other hand, has a separate memory location for each of its elements and
they all can be used at once.
To give a concrete example of their use, I was
working on a Scheme interpreter a little while ago and I was essentially
overlaying the Scheme data types onto the C data types. This involved storing
in a struct an enum indicating the type of value and a union to store that
value.
union foo {
int a; // can't use both a and b at once
char b;
} foo;
struct bar {
int a; // can use both a and b simultaneously
char b;
} bar;
union foo x;
x.a = 3; // OK
x.b = 'c'; // NO! this affects the value of x.a!
struct bar y;
y.a = 3; // OK
y.b = 'c'; // OK
int a; // can't use both a and b at once
char b;
} foo;
struct bar {
int a; // can use both a and b simultaneously
char b;
} bar;
union foo x;
x.a = 3; // OK
x.b = 'c'; // NO! this affects the value of x.a!
struct bar y;
y.a = 3; // OK
y.b = 'c'; // OK
edit: If you're wondering
what setting x.b to 'c' changes the value of x.a to, technically speaking it's
undefined. On most modern machines a char is 1 byte and an int is 4 bytes, so
giving x.b the value 'c' also gives the first byte of x.a that same value:
union foo x;
x.a = 3;
x.b = 'c';
printf("%i, %i\n", x.a, x.b);
x.a = 3;
x.b = 'c';
printf("%i, %i\n", x.a, x.b);
prints
99, 99
Why are the two values the same? Because the
last 3 bytes of the int 3 are all zero, so it's also read as 99. If we put in a
larger number for x.a, you'll see that this is not always the case:
union foo x;
x.a = 387439;
x.b = 'c';
printf("%i, %i\n", x.a, x.b);
x.a = 387439;
x.b = 'c';
printf("%i, %i\n", x.a, x.b);
prints
387427, 99
To get a closer look at the actual memory
values, let's set and print out the values in hex:
union foo x;
x.a = 0xDEADBEEF;
x.b = 0x22;
printf("%x, %x\n", x.a, x.b);
x.a = 0xDEADBEEF;
x.b = 0x22;
printf("%x, %x\n", x.a, x.b);
prints
deadbe22, 22
You can clearly see where the 0x22 overwrote the
0xEF.
BUT
In C, the order of bytes in an int are not
defined. This program overwrote the 0xEF with 0x22 on my Mac, but there
are other platforms where it would overwrite the 0xDE instead because the order
of the bytes that make up the int were reversed. Therefore, when writing a
program, you should never rely on the behavior of overwriting specific data in
a union because it's not portable.

Extern Keyword
I’m sure that this post will be as interesting and informative to
C virgins (i.e. beginners) as it will be to those who are well versed in C. So
let me start with saying that extern keyword applies to C variables (data
objects) and C functions. Basically extern keyword extends the visibility of
the C variables and C functions. Probably that’s is the reason why it was named
as extern.
Though (almost) everyone knows the meaning of declaration and
definition of a variable/function yet for the sake of completeness of this
post, I would like to clarify them. Declaration of a variable/function simply
declares that the variable/function exists somewhere in the program but the
memory is not allocated for them. But the declaration of a variable/function
serves an important role. And that is the type of the variable/function.
Therefore, when a variable is declared, the program knows the data type of that
variable. In case of function declaration, the program knows what are the
arguments to that functions, their data types, the order of arguments and the
return type of the function. So that’s all about declaration. Coming to the
definition, when we define a variable/function, apart from the role of
declaration, it also allocates memory for that variable/function. Therefore, we
can think of definition as a super set of declaration. (or declaration as a
subset of definition). From this explanation, it should be obvious that a
variable/function can be declared any number of times but it can be defined
only once. (Remember the basic principle that you can’t have two locations of
the same variable/function). So that’s all about declaration and definition.
Now coming back to our main objective: Understanding “extern”
keyword in C. I’ve explained the role of declaration/definition because it’s
mandatory to understand them to understand the “extern” keyword. Let us first
take the easy case. Use of extern with C functions. By default, the declaration
and definition of a C function have “extern” prepended with them. It means even
though we don’t use extern with the declaration/definition of C functions, it
is present there. For example, when we write.
int foo(int arg1, char arg2);
There’s an extern present in the beginning which is hidden and the
compiler treats it as below.
extern int foo(int arg1,
char arg2);
Same is the case with the definition of a C function (Definition
of a C function means writing the body of the function). Therefore whenever we
define a C function, an extern is present there in the beginning of the
function definition. Since the declaration can be done any number of times and
definition can be done only once, we can notice that declaration of a function
can be added in several C/H files or in a single C/H file several times. But we
notice the actual definition of the function only once (i.e. in one file only).
And as the extern extends the visibility to the whole program, the functions
can be used (called) anywhere in any of the files of the whole program provided
the declaration of the function is known. (By knowing the declaration of the function,
C compiler knows that the definition of the function exists and it goes ahead
to compile the program). So that’s all about extern with C functions.
Now let us the take the second and final case i.e. use of extern
with C variables. I feel that it more interesting and information than the
previous case where extern is present by default with C functions. So let me
ask the question, how would you declare a C variable without defining it? Many
of you would see it trivial but it’s important question to understand extern
with C variables. The answer goes as follows.
extern int var;
Here, an integer type variable called var has been declared
(remember no definition i.e. no memory allocation for var so far). And we can
do this declaration as many times as needed. (remember that declaration can be
done any number of times) So far so good.
Now how would you define a variable. Now I agree that it is the
most trivial question in programming and the answer is as follows.
int var;
Here, an integer type variable called var has been declared as
well as defined. (remember that definition is the super set of declaration).
Here the memory for var is also allocated. Now here comes the surprise, when we
declared/defined a C function, we saw that an extern was present by default.
While defining a function, we can prepend it with extern without any issues.
But it is not the case with C variables. If we put the presence of extern in
variable as default then the memory for them will not be allocated ever, they
will be declared only. Therefore, we put extern explicitly for C variables when
we want to declare them without defining them. Also, as the extern extends the
visibility to the whole program, by externing a variable we can use the
variables anywhere in the program provided we know the declaration of them and
the variable is defined somewhere.
Now let us try to understand extern with examples.
Example 1:
int var;
int main(void)
{
var = 10;
return 0;
}
|
Analysis: This program is compiled successfully. Here var is
defined (and declared implicitly) globally.
Example 2:
extern int var;
int main(void)
{
return 0;
}
|
Analysis: This program is compiled successfully. Here var is
declared only. Notice var is never used so no problems.
Example 3:
extern int var;
int main(void)
{
var = 10;
return 0;
}
|
Analysis: This program throws error in compilation. Because var is
declared but not defined anywhere. Essentially, the var isn’t allocated any
memory. And the program is trying to change the value to 10 of a variable that
doesn’t exist at all.
Example 4:
#include "somefile.h"
extern int var;
int main(void)
{
var = 10;
return 0;
}
|
Analysis: Supposing that somefile.h has the definition of var.
This program will be compiled successfully.
Example 5:
extern int var = 0;
int main(void)
{
var = 10;
return 0;
}
|
Analysis: Guess this program will work? Well, here comes another
surprise from C standards. They say that..if a variable is only declared and an
initializer is also provided with that declaration, then the memory for that
variable will be allocated i.e. that variable will be considered as defined.
Therefore, as per the C standard, this program will compile successfully and
work.
So that was a preliminary look at “extern” keyword in C.
I’m sure that you want to have some take away from the reading of
this post. And I would not disappoint you.
In short, we can say
In short, we can say
1. Declaration can be done
any number of times but definition only once.
2. “extern” keyword is used to extend the visibility of variables/functions().
3. Since functions are visible through out the program by default. The use of extern is not needed in function declaration/definition. Its use is redundant.
4. When extern is used with a variable, it’s only declared not defined.
5. As an exception, when an extern variable is declared with initialization, it is taken as definition of the variable as well.
2. “extern” keyword is used to extend the visibility of variables/functions().
3. Since functions are visible through out the program by default. The use of extern is not needed in function declaration/definition. Its use is redundant.
4. When extern is used with a variable, it’s only declared not defined.
5. As an exception, when an extern variable is declared with initialization, it is taken as definition of the variable as well.
What is the aim of GMEM and LOCATE?
The memories of the most
performant computation devices are random accessed memories (RAM). It implies
that each contained element have a unique address to access it. The bigger the
memory will be, the wider the addresses will become. As a consequence, these
addresses have to be stored in the executed code, and this takes place.
Fortunately, a lot of algorithms are using only a few amount of data, so it is
possible to reduce the space needed to store the memory addresses by improving
the addressing mechanism.
For this reason, several
addressing mechanisms have been implemented on CPUs. In the code, different
addressing mechanisms requires different opcode, so the compiler have to know
which addressing mechanism to be used when it compiles the code. Depending on
where the data is in memory, the most efficient addressing mechanism shall be
used, if not, the code will be bigger and slower (but still be working).
Hence the information on
data allocation in memory is necessary to compile a C file. This information is
provided to the compiler by a compiler specific mechanism. To allow the
independence of the C file content towards the compiler, the GMEM has been
created. Moreover, the addressing mechanisms themselves are microcontroller
specific, and some addressing mechanisms are only available on some
microcontrollers.
The role of GMEM is quite
difficult because it has to provide as output a controller specific addressing
mechanism and take as input only microcontroller and compiler independent
information.
No comments:
Post a Comment